数据分析练习(2018)
任务三、本阶段的任务是:film_log3.csv中包含了来自不同城市中多个影院的电影票房信息, 你的小组通过编程完成对文件film_log3.csv中电影信息数据的清洗和整理,并完成数据计算、分析 和表达任务。(20分) 本竞赛任务的赛前抽取参数是:电影名称A、B、C 和地名M市、N市以及数据文件 film_log3.csv,选手可在竞赛环境的arg0300.txt文件中获得A、B、C、M、N的值。本阶段任 务,需要参赛学生提交每个小题涉及到的所有ansXXXX.jpg、ansXXXX.py、ansXXXX.dat文件 (XXXX相关指数字,xx任务编码:03.第3、4位编码XX为賽题的编码01、02、03、04等)。
电影:A:大世界、B:捉妖记2、C:红海行动
城市:M:北京、N:苏州
Q1
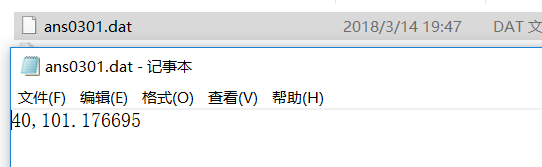
编程统计并输出影片A的上映天数和日平均票房(日平均票房指文件中的所有涉及城市总平 均票房),程序源代码保存成ans0301.py,并将结果保存于ans0301.dat,要求ans0301.dat只包 含1个long型数据和一个1个浮点型数据,浮点数据以万元为单位,保留6位小数,2个数以英文逗 号分隔,不换行,文件样例如下:
123, 23.123456
解题过程:
#encoding:utf-8
import numpy as np
import pandas as pd
if __name__=="__main__":
name=["time","filmName","place","dyy","pf"] #列名
data=pd.read_csv("film.csv",names=name) #读取CSV并设置列名
days=len(data[data.filmName=="大世界"].time.unique()) #获取大世界这本电影的上映的日期(去重)
average_money=data[data.filmName=="大世界"].sum()["pf"]/float(days) #求出大世界这部电影的日平均票房(单位:元)
average_money=average_money/10000.0 #将单位元转化为万元
result="{},{:.6f}".format(days,average_money) #准备插入的文本
f=open("ans0301.dat","w") #新建文件
f.write(result) #写入准备的字符串
f.close()
生成文件效果图:
Q2
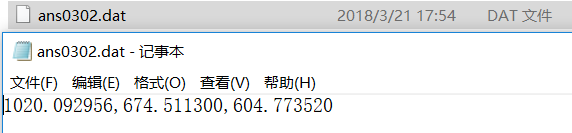
2、利用Bar函数编程输出影片A、B、C的周平均票房(周平均票房指文件中的所有涉及城市周 票房总平均),Y轴表示票房收入,单位万元;X轴表示电影名称,电影名称的排列从左至右以A、 B、C为准,要求将输出的直方图保存成图像文件ans0302.jpg,程序源代码保存成ans0302.py, 另外,将三部电影各自的票房总收入按自高到低的顺序存入ans0302.dat文件中,要求 ans0302.dat中只包含3个浮点型票房数据,以万元为单位,保留6位小数,数据以英文逗号分隔, 不换行,文件样例如下:
23.123456,20.654321,18.123456
对本题周票房的说明如下:若某部电影从某月2日开始上映,则从当月2日到8日为其第1周票 房,9日至15日为其第2周票房,不满1周按1周计算以此类推。
解题过程:
#encoding:utf-8
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def get_weeks(days):
weeks_tmp=days // 7
if days % 7 != 0:
weeks = weeks_tmp + 1
return weeks*1.0
return weeks_tmp*1.0
if __name__=="__main__":
name = ["time", "filmName", "place", "dyy", "pf"]
data = pd.read_csv("film.csv", names=name)
# A电影的周平均票房
days_A = len(data[data.filmName=="大世界"].time.unique())
zpf_A = data[(data.filmName == "大世界")].sum()["pf"]
weekpf_A = zpf_A / get_weeks(days_A)
weekpf_A=weekpf_A/10000.0
# B电影的周平均票房
days_B = len(data[data.filmName=="捉妖记2"].time.unique())
zpf_B = data[data.filmName == "捉妖记2"].sum()["pf"]
weekpf_B = zpf_B / get_weeks(days_B)
weekpf_B=weekpf_B/10000.0
# C电影的周平均票房
days_C = len(data[data.filmName=="红海行动"].time.unique())
zpf_C = data[data.filmName == "红海行动"].sum()["pf"]
weekpf_C = zpf_C / get_weeks(days_C)
weekpf_C=weekpf_C/10000.0
dy_names = ["大世界", "捉妖记2", "红海行动"]
dy_data = [weekpf_A, weekpf_B, weekpf_C]
# A画图并保存
plt.bar(dy_names, dy_data)
plt.savefig("ans0302.jpg") #此处需要安装pillow,如果没有安装,保存成jpg会直接报错。
#可以先保存成png,然后用画图工具保存成jpg
dy_data=sorted(dy_data,reverse=True)
# 将结果写入文件
result_string = "%.6f,%.6f,%.6f"%tuple(dy_data)
print result_string
f = open("ans0302.dat", "w")
f.write(result_string)
f.close()
绘制的图片:
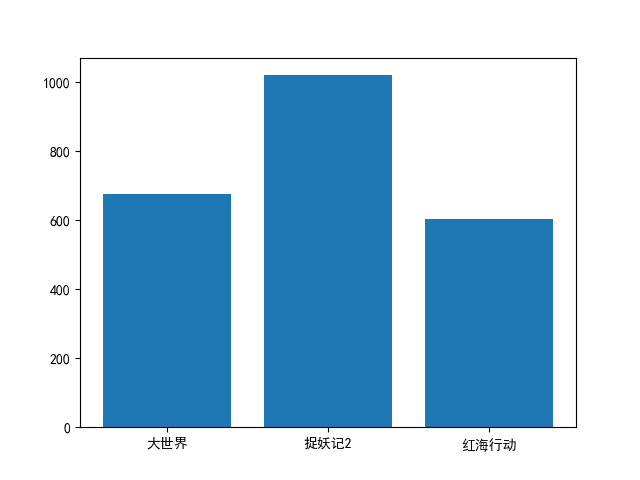 注,因为暂时没有修改matplotlib的配置文件支持中文。
注,因为暂时没有修改matplotlib的配置文件支持中文。
ans0302.dat数据展示:
Q3
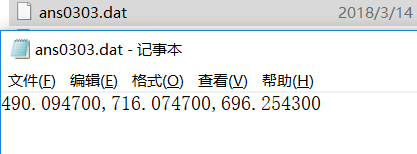
3、编程,利用折线图,画出影片A、B、C各自的周票房(周票房指文件中的所有涉及城市总周 票房)收入变化,要求将输出的折线图保存成图像文件ans0303.jpg,程序源代码保存成 ans0303.py,Y轴表示票房收入,单位为“万元”;X轴表示时间,以“0、1、2、3…n”的非负 整数作为刻度值,单位为“周”,要求: 1)折线图中含图例; 2)三部电影用不同的颜色和线型表达; 3)将电影A第一周的票房收入,电影B第二周的票房收入,电影C第三周的票房收入顺序存入 ans0303.dat文件中,注意ans0303.dat只包含3个浮点型票房数据,以万元为单位,保留6位小数,数据以英文逗号分隔,不换行,文件样例如下:
23.123456,20.654321,18.123456
4)对本题周票房的说明如下:若某部电影从某月2日开始上映,则从当月2日到8日为其第一周 票房,9日至15日为其第2周票房,以此类推.
解答过程:
#encoding:utf-8
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
name = ["time", "filmName", "place", "dyy", "pf"]
data=pd.read_csv("film.csv",names=name)
data.time=data.time.apply(lambda x:pd.to_datetime(x,format="%Y-%m-%d"))
data["weekofyear"]=data.time.apply(lambda x:x.weekofyear)
filmlist=["大世界","捉妖记2","红海行动"]
tmp_A=data[data.filmName=="大世界"].groupby(["weekofyear"]).sum()/10000.0
tmp_B=data[data.filmName=="捉妖记2"].groupby(["weekofyear"]).sum()/10000.0
tmp_C=data[data.filmName=="红海行动"].groupby(["weekofyear"]).sum()/10000.0
tmp_A.reset_index(inplace=True)
tmp_B.reset_index(inplace=True)
tmp_C.reset_index(inplace=True)
A1=np.array(tmp_A)[0][1]
B1=np.array(tmp_B)[1][1]
C1=np.array(tmp_C)[2][1]
l1,=plt.plot(tmp_A.index,tmp_A.pf,ls="-")
l2,=plt.plot(tmp_B.index,tmp_B.pf,ls="-.")
l3,=plt.plot(tmp_C.index,tmp_C.pf,ls=":")
plt.legend(handles=[l1,l2,l3],labels=[u"电影A",u"电影B",u"电影C"])
plt.xlabel("weeks")
plt.ylabel("Money")
plt.savefig("ans0303.jpg")
# #此处需要安装pillow,如果没有安装,保存成jpg会直接报错。
# #可以先保存成png,然后用画图工具保存成jpg
plt.show()
result_string="{:.6f},{:.6f},{:.6f}".format(A1,B1,C1)
f=open("ans0303.dat","w")
f.write(result_string)
f.close()
绘制的图片
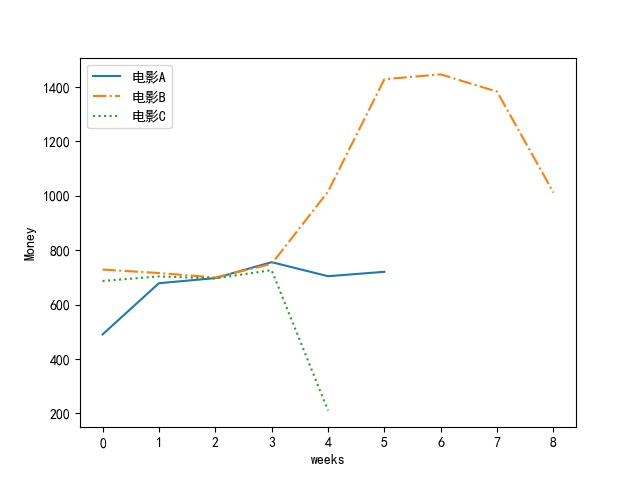 注:因为数据为生成的,图片有些许奇怪。
注:因为数据为生成的,图片有些许奇怪。
ans0303.dat内容展示:
 修改上面图片中框出的文件。
修改上面图片中框出的文件。