画图
画图第一步,自然是导入画图所需要用到的函数。虽然我们画图用matplotlib,但是需要知道的是pandas也可以用来画图,并且十分便利。为了方便下来的实践。我们一次性将所需要用到的库导入。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
折线图
折线图是我最早接触的图像,可以使用plot函数很方便的画出来,也许是因为方便,我对这个函数印象深刻。 x、y、折线标签、颜色、粗细,线形,简单的几个几个参数就可以画出比较漂亮的图。
y=[10,23,34,23,45,31,23,13,43]
x=[0,1,2,3,4,5,6,7,8]
plt.plot(x,y,label="line",color="R",linewidth=1.0,linestyle="--")
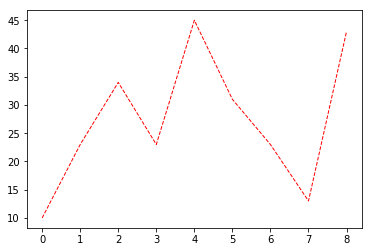 到这里,折线图就画好了,但是是不是感觉图片有点小,看着不太舒服。没关系,我们只要在画图前设置画图区域的大小就可以了。下面我们就来看一下如何设置画图区域(对象)的大小。
到这里,折线图就画好了,但是是不是感觉图片有点小,看着不太舒服。没关系,我们只要在画图前设置画图区域的大小就可以了。下面我们就来看一下如何设置画图区域(对象)的大小。
设置绘图对象大小
我们使用plt.figure(figuresize=(10,10),dpi=72)来设置对象大小,并且可以设置图片的清晰度(dpi)。
plt.figure(figsize=(10,10),dpi=72)
plt.plot(x,y,label="line",color="R",linewidth=1.0,linestyle="--")
 现在比上面大一点了!
现在比上面大一点了!
柱状图
柱状图的画法与折线图非常相似,几乎我们只需要将折线图的plot改为bar就可以达成我们的目的。
y=[10,23,34,23,45,31,23,13,43]
x=[0,1,2,3,4,5,6,7,8]
plt.bar(x,y,color="#66ccff",width=0.35,edgecolor="red")
 下来解释一下,新用到的参数
下来解释一下,新用到的参数edgecolor相信大家也都看到了,我将edgecolor设置为红色,柱状图的周围就有了一个红色的边框。但是这似乎还是缺点什么,,仔细想想,每一列的准确值,我将如何得到?
绘制柱状图列顶部数据
为柱状图顶部添加具体数据。在上面画柱状图的基础上添加下面两行代码。
for x1,y1 in zip(x,y):
plt.text(x1,y1+0.05,'%.2f' %y1,ha='center')
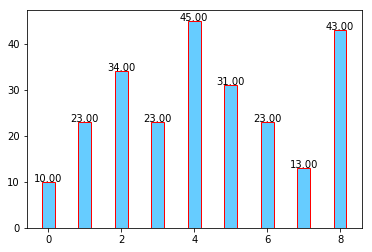 这时候,我们已经解决了上面提出的问题。在每一列都标上了数据。
这时候,我们已经解决了上面提出的问题。在每一列都标上了数据。
散点图
我们继续沿用上面的数据,来画一下最简单的散点图。我们通常用散点图来观察发现数据的分布规则。
plt.scatter(x,y)
 当然,上面的数据是我随便取的看不出什么规则,我们再看看
当然,上面的数据是我随便取的看不出什么规则,我们再看看scatter函数的其他参数。
参数
示例
含义
marker
“o”
圈的意思,还有很多可以用的符号,如“*”,“+”,倒三角“v”,正方形“s”
alpha
默认None
调整点的透明度,范围0-1
norm
默认:None
调整点的亮度,范围0-1(float数据)
color
默认颜色
调整点的颜色,可简写为c
下面,我们用上这些参数来进行画图。数据依旧为上面用到的xy值。
plt.scatter(x,y,marker="o",color="green",alpha=0.2,norm=0.4)
 上面的图片就是我们这条函数所画出来的效果。
上面的图片就是我们这条函数所画出来的效果。
饼图
饼图跟上面的那些略有相似之处,但是最简单的饼图只需要一个值,那就是,每一份占总体的值,值得注意的是,当sum(x)>1时,会进行归一化处理。
dy=[10,30,25,5,15,10,5]
plt.pie(dy)
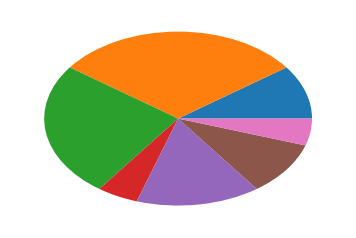 下面来补充一下
下面来补充一下pie函数的参数
参数
说明
形式
x
每一块所占的比重
列表
labels
每一块饼外侧显示说明文字
列表
starttangle
绘制的方向,默认x正半轴逆时针开始,当设置为90°时,从y轴正半轴开始
数字
shadow
设置是否有阴影效果
True或False
labeldistance
标签位置
相对于半径的比例, 如<1则绘制在饼图内侧
autopct
控制饼图百分比
‘%1.1f’
radius
控制饼图半径
数字
我们带上参数来再画一次。
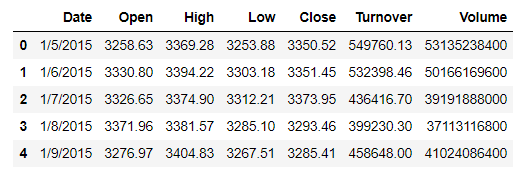
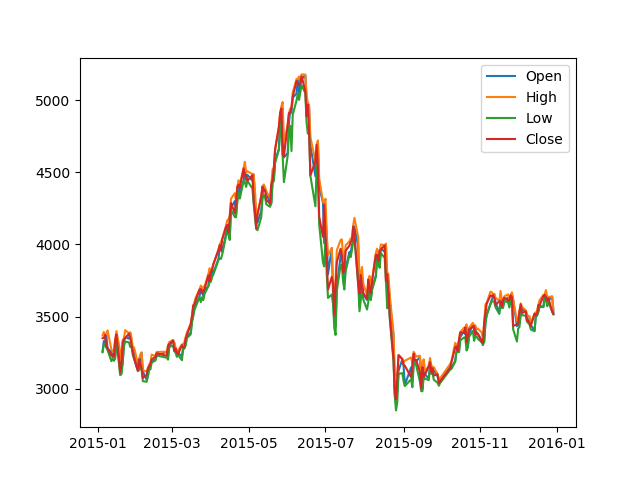
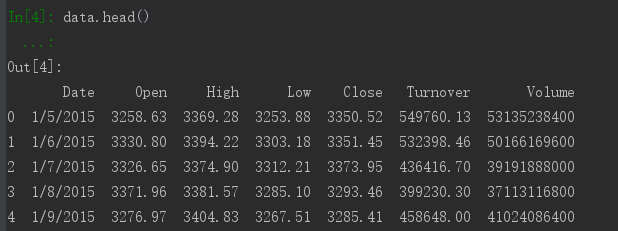

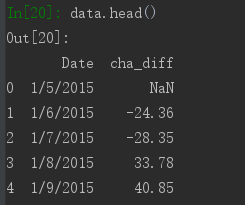
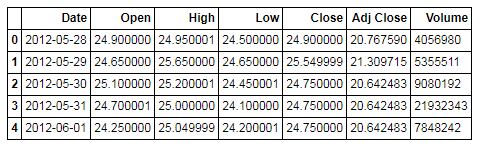
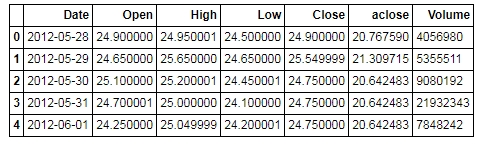
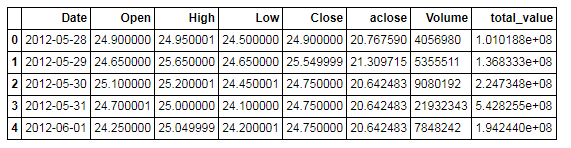

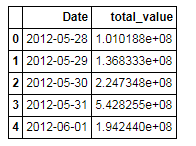
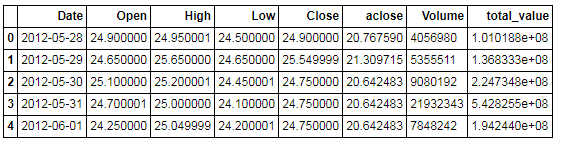


 下来将列表重新转化为DateFrame.
下来将列表重新转化为DateFrame.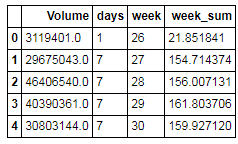
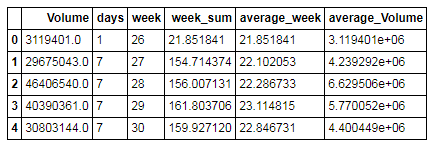
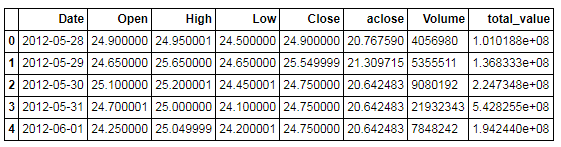
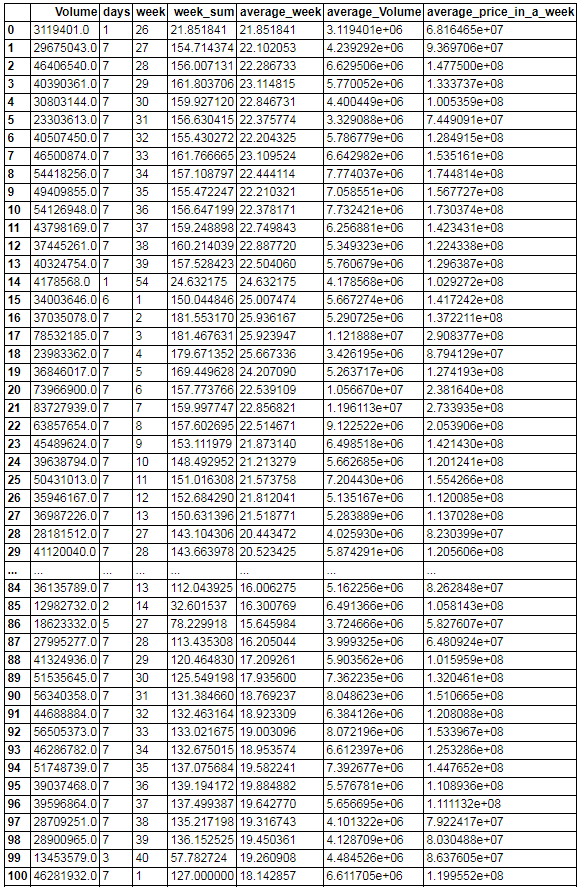 截图比较长,因此放出部分内容。
截图比较长,因此放出部分内容。