火狐xpath cheaker插件
- 用来验证手写的xpath是否正确
- 需要使用Firefox 45.0.2(关闭更新)
火狐浏览器firebug插件
- 用来查看HTML代码
- 分析浏览器请求
很高兴的启用类Git,因为Git可以更加方便的为团队合作提供合并代码等需求。目前我尚处于Git自学阶段,在下来的时间里,实践项目将会将全部源码上传码云。
另外,附上Git使用教程。 附: Git教程推荐列表 1. Git教程 - 廖雪峰的官方网站 2. Pro Git(中文版)
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
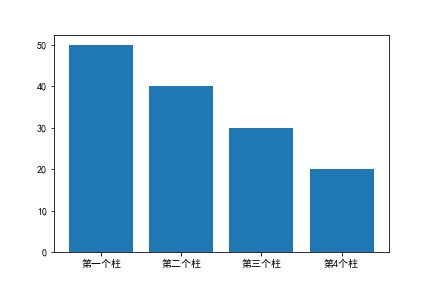
x=["第一个柱","第二个柱","第三个柱","第4个柱"]
y=[50,40,30,20]
plt.bar(x,y)
plt.show()
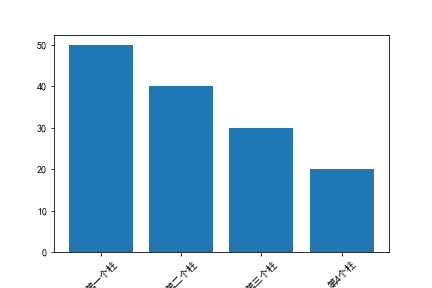
plt.bar(x,y)
plt.xticks(rotation="45")
plt.savefig("45旋转.png")
plt.show()
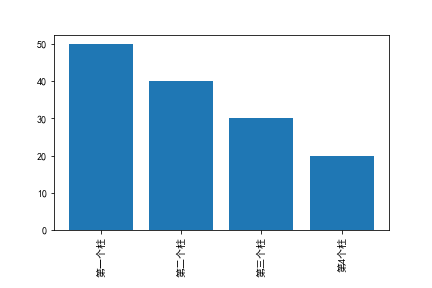
plt.figure(figsize=(5,5),dpi=300)
plt.bar(x,y)
plt.xticks(rotation="90",fontsize=20)
plt.subplots_adjust(bottom=0.2) #因为竖着字太长,生成图片中的x轴标签会被截取。因此设置距离底部0.2
plt.savefig("90旋转.png")
plt.show()
1.1 在python3安装jupyter
py -3 -m pip install jupyter
2.1 在命令提示框输入
cd E:\jupyter #一会jupyter在这个目录打开
jupyter notebook #可以指定端口
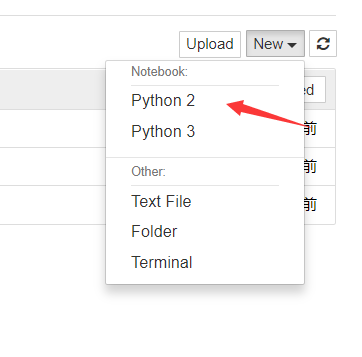
这样我们就安装完成jupyter,但是新建的文档只有一个Python3的选项。
3.1 安装ipykernel
py -3 -m pip install ipykernel
py -2 -m pip install ipykernel #2的这句会报错
报错情况如下所示。 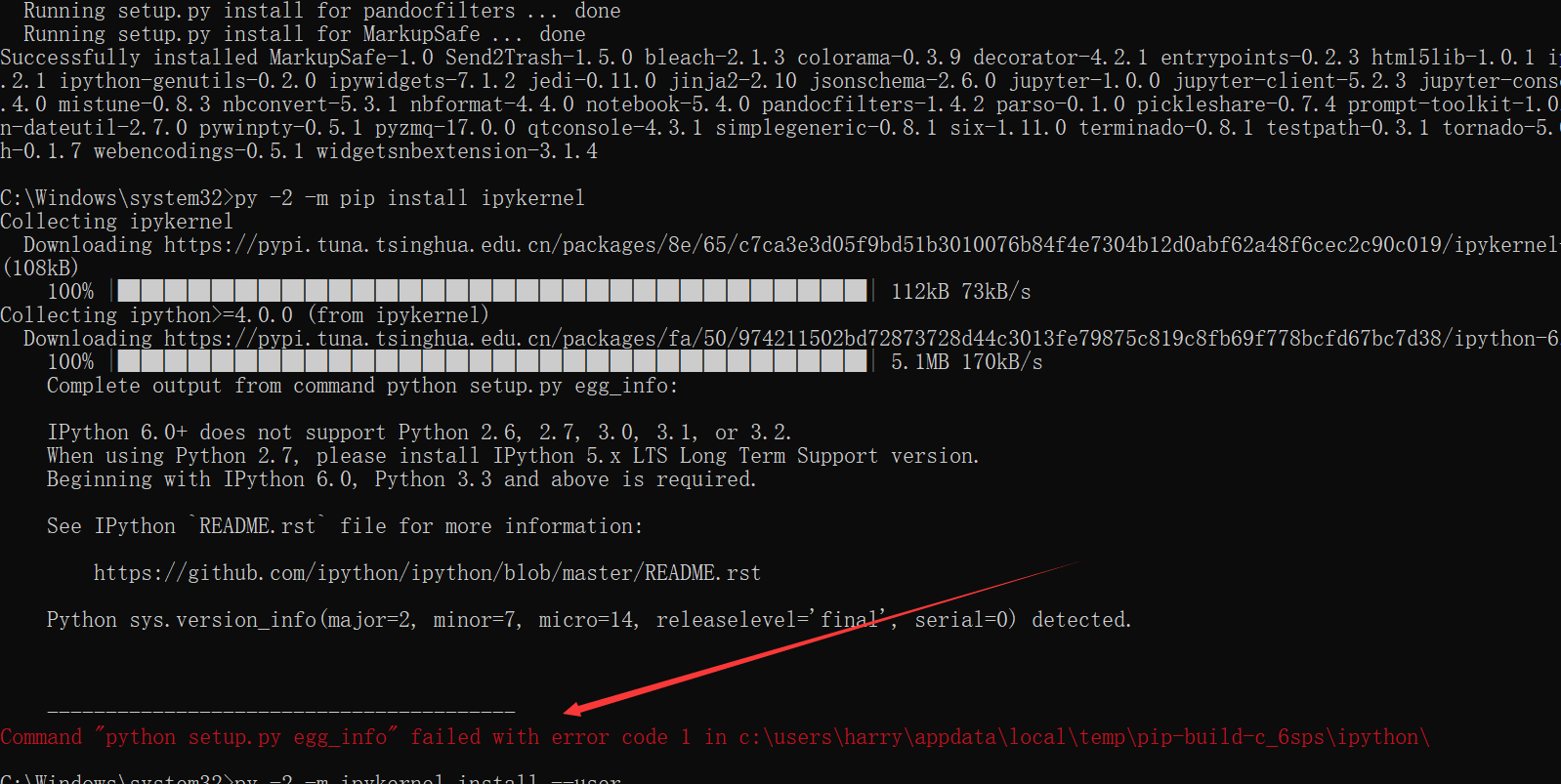 解决方法如下:
解决方法如下:
py -2 -m pip install ipykernel==8888 #先指定一个错误的版本,在返回的错误信息中会有版本列表。
py -2 -m pip install ipykernel==4.8.2 #指定上述列表版本内的一个版本
返回列表如下:  3.2 配置ipykernel
3.2 配置ipykernel
py -2 -m ipykernel install --user
最近一直纠结,自己文章的图片该放在哪里,我上传到图床会保留多少天?在知乎上面,发现普遍的答案是用七牛云的对象存储,似乎七牛云的对象存储做的还不错,有许多人用七牛来上传,保存自己的MarkDown笔记图片。网上一搜,我们也可以发现专门用来传图片的Mpic工具。但是始终找不到阿里云的上传工具。为此,我查阅了阿里云官方的OSS文档。下面简单展示一个Demo。
pip install oss2 #用于图片的上传
pip install pyperclip #用于MarkDown图片代码的复制
pip install requests #获取远程图片
#encoding:utf-8
import oss2
import os
import datetime
import pyperclip
import requests
def upload(bucket):
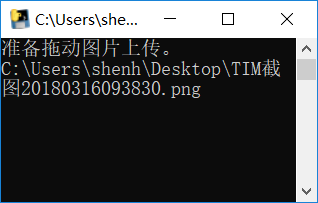
filePath = str(input()).strip() #去除链接/路径前后的空格
if filePath=="":
return
fileName = os.path.basename(filePath) #提取文件名
if "https://" in filePath: #判断是否为网络文件(是否需要下载)
r=requests.get(filePath)
with open(fileName,"ab") as tmp:
tmp.write(r.content)
filePath=fileName
now = datetime.datetime.now()
t = now.strftime("%Y_%m_%d_%H_%M_%S_")
remoteFileName = 'Markdown_image/' + str(t) + fileName #设置远程文件名
result = bucket.put_object_from_file(remoteFileName, filePath) #上传文件
if result.status == 200:
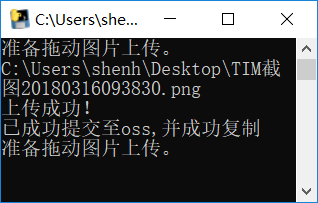
print("上传成功!")
my_web_adress = "https://harrycode.cn/" #自己绑定OSS的域名,需要通过备案
remote_file_adress = my_web_adress + remoteFileName+" "
mkstyle="".format(remote_file_adress) #生成MarkDown语法的图片链接
pyperclip.copy(mkstyle) #复制到剪贴板
print("已成功提交至oss,并成功复制")
os.remove(filePath) #删除本地文件
else:
print(result.status)
print("网络出错,或出现其他未知原因!")
if __name__=="__main__":
AccessKeyID="123456"
AccessKeySeret="abcdef"
auth = oss2.Auth(AccessKeyID, AccessKeySeret) #认证
service = oss2.Service(auth=auth, endpoint='oss-cn-shanghai.aliyuncs.com')
bucket = oss2.Bucket(auth, 'oss-cn-shanghai.aliyuncs.com', "harrycodesitefile") #创建用来上传文件的的bucket
while(True):
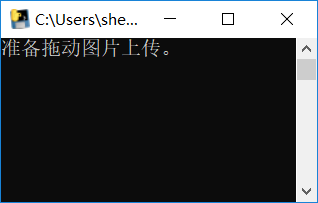
print("准备拖动图片上传。")
upload(bucket)