查看本地Python库说明文件
python -m pydoc -p 1234 (1234为自定义端口号)
#浏览器输入 localhost:自定义端口
 单纯的看英语,可能比较困难,还好我们有Chrome浏览器
单纯的看英语,可能比较困难,还好我们有Chrome浏览器  再点击翻译选项后,页面就变成了这个样子
再点击翻译选项后,页面就变成了这个样子 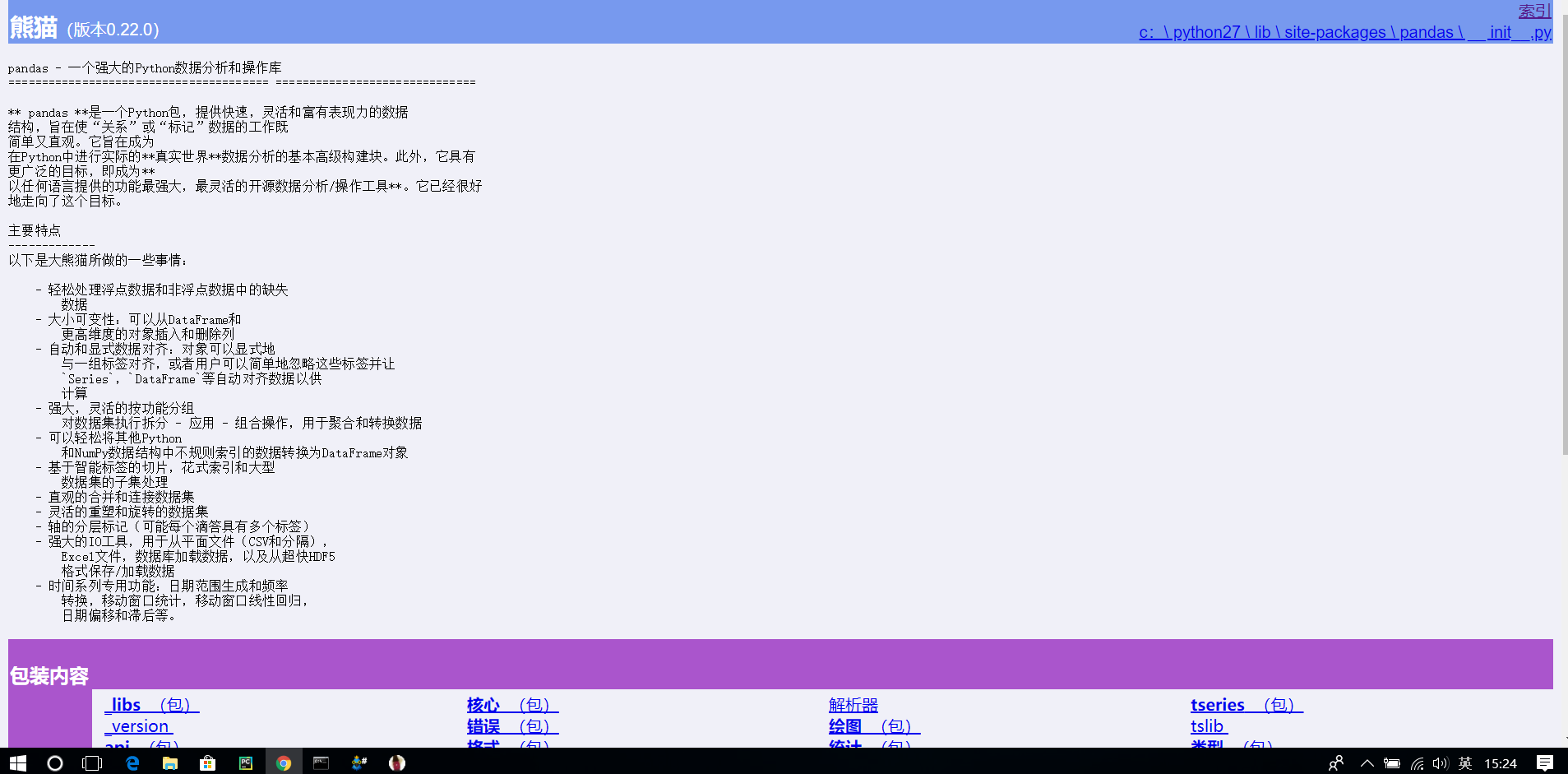
1、Linux基础知识 2、Ubuntu14.04TLS 3、hadoop安装包
adduser hadoop
passwd hadoop
sudo apt-get update #更新后才可用吗default-jdk安装
sudo apt-get install default-jdk
mkdir hadoop_download
cd hadoop_download
wget http://archive.apache.org/dist/hadoop/core/hadoop-2.7.1/hadoop-2.7.1.tar.gz
注:上面的网址有时下载缓慢,不稳定,可以选中下面的附件,右键复制链接地址,替换上述网址。(附件位于文末【文章存档链接中】)格式为:
wget --no-check-certificate [https://网址]
因为网址为https因此需要加–no-check-certificate参数
su #切换root用户
vim /etc/sudoers #若编辑器不存在,请执行sudo apt-get install vim
#在 root ALL=(ALL:ALL) ALL下方新增
hadoop ALL=(ALL:ALL) ALL
#保存并退出vim编辑器
su hadoop #切换回hadoop用户
sudo apt-get install openssh-server
#测试安装是否成功
ssh localhost
#输入yes后输入密码成功看到以下消息为成功
Last login: Wed Jan 17 21:08:16 2018 from desktop-eeg1rso.lan
hadoop@ubuntu:~$
sudo tar -zxvf hadoop_2.7.1.tar.gz -C /usr/local/
解释参数zxvf x : 从 tar 包中把文件提取出来 z : 表示 tar 包是被 gzip 压缩过的,所以解压时需要用 gunzip 解压 v : 显示详细信息 f xxx.tar.gz : 指定被处理的文件是 xxx.tar.gz tar -C指定解压的目录【来源网络】
cd /usr/local/
sudo chmod a+W hadoop-2.7.1/
cd hadoop-2.7.1/etc/hadoop/
ll
如下图所示:  我们需要配置以下几个文件:
我们需要配置以下几个文件:
hadoop-env.sh
core-site.xml
hdfs-site.xml
因为我们使用apt安装Java因此,需要找出安装的路径
which java
ls -lar /usr/bin/java
ls -lar /etc/alternatives/java
ls -lar /usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java
#当路径不在发生改变时,我们即找到了安装目录过程如下图所示
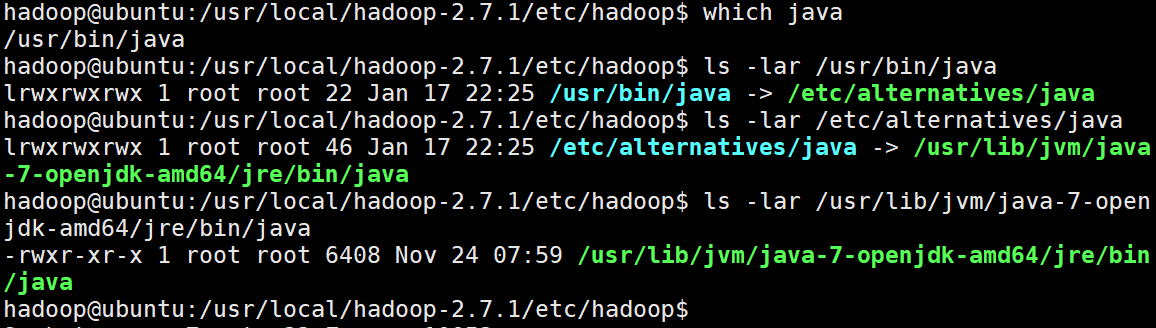
因此Java的目录为:
/usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java
sudo vim hadoop-env.sh
#修改下图的JAVA_HOME
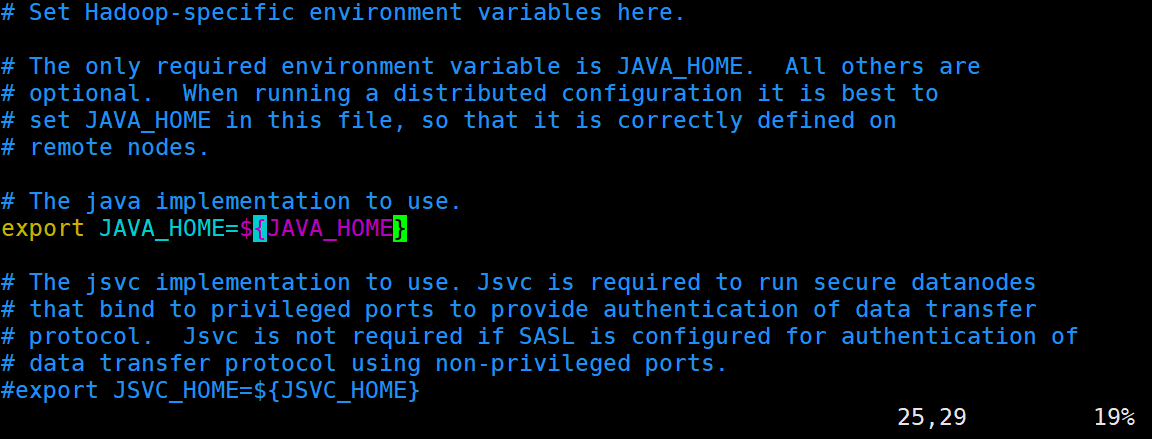
/usr/lib/jvm/java-7-openjdk-amd64/jre
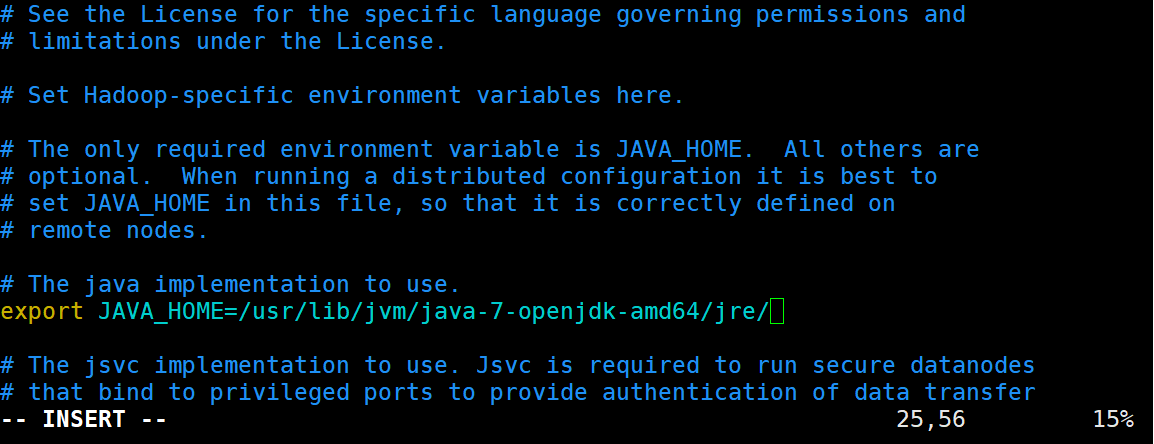
mkdir /home/hadoop/hadoop_tmp_data
sudo vim core-site.xml
加入configuration标记之间
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop_tmp_data</value>
</property>
sudo vim hdfs-site.xml
加入configuration标记之间
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
cd /usr/local/hadoop-2.7.1/
./bin/hdfs namenode -format
看到Storage directory /home/hadoop/hadoop_tmp_data/dfs/name has been successfully formatted.意味着namenode格式化成功。如下图 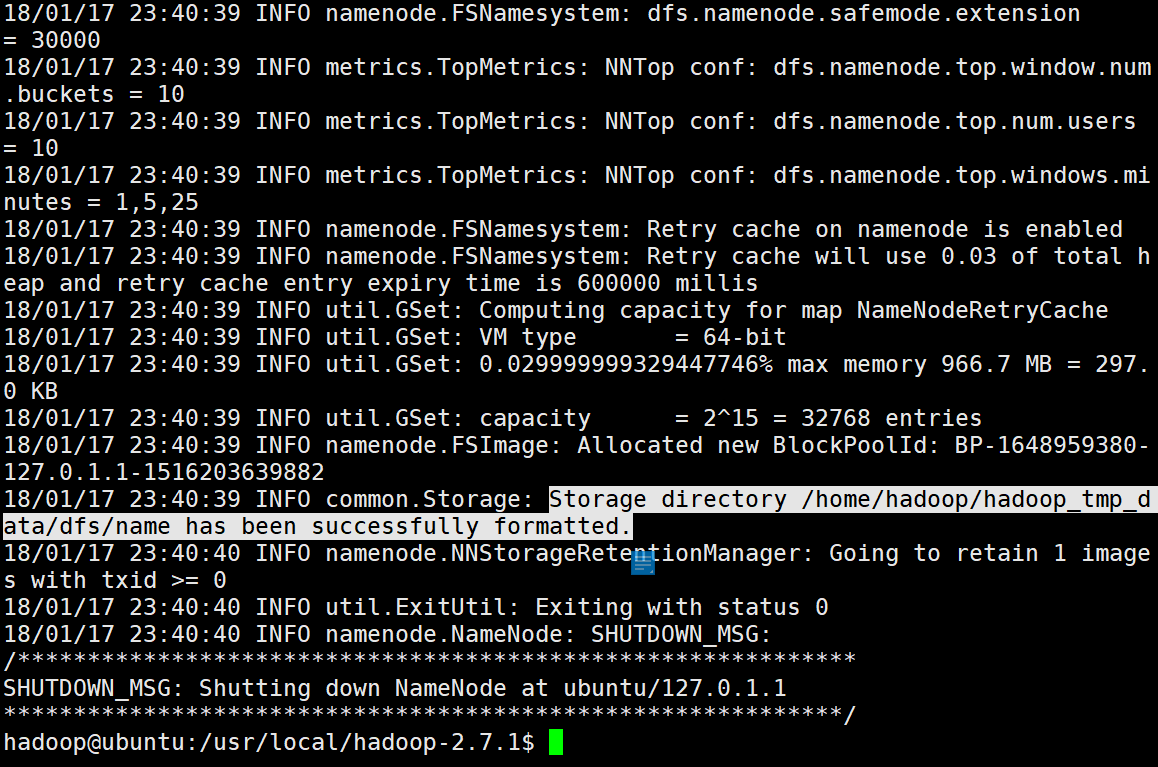
./sbin/start-dfs.sh
#下来会输好几次密码
结果如图 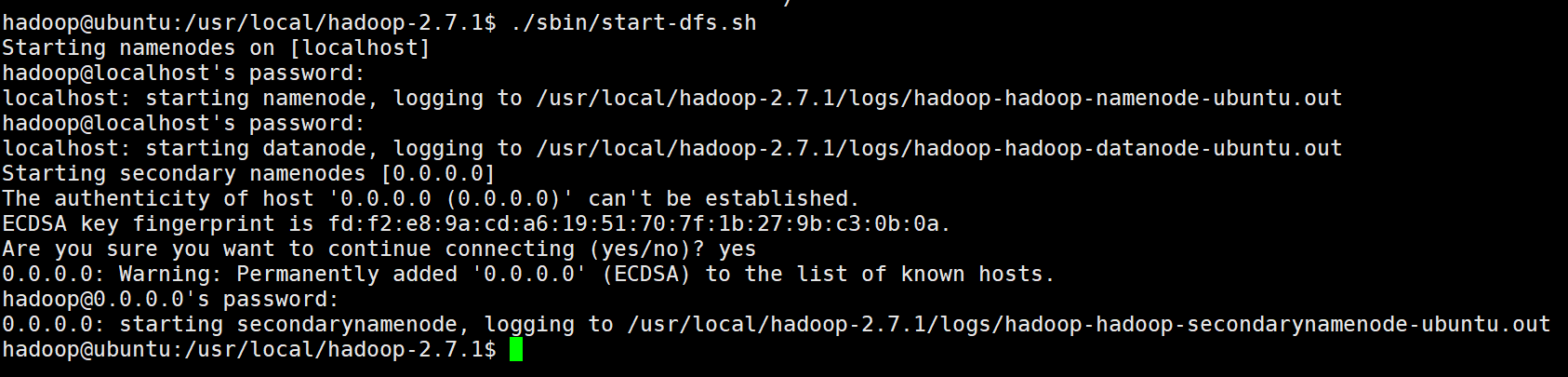
jps
输入后应如下图 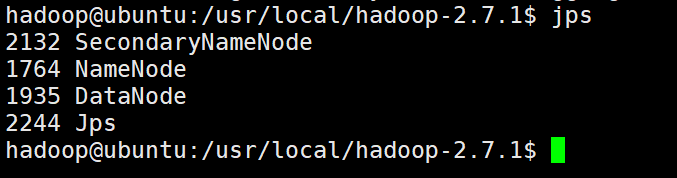
./bin/hdfs dfs -mkdir -p /user/hadoop
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
./bin/hdfs dfs -ls input #查看创复制的文件列表
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+' #执行测试
./bin/hdfs dfs -cat output/* #输出结果
输出结果如下: 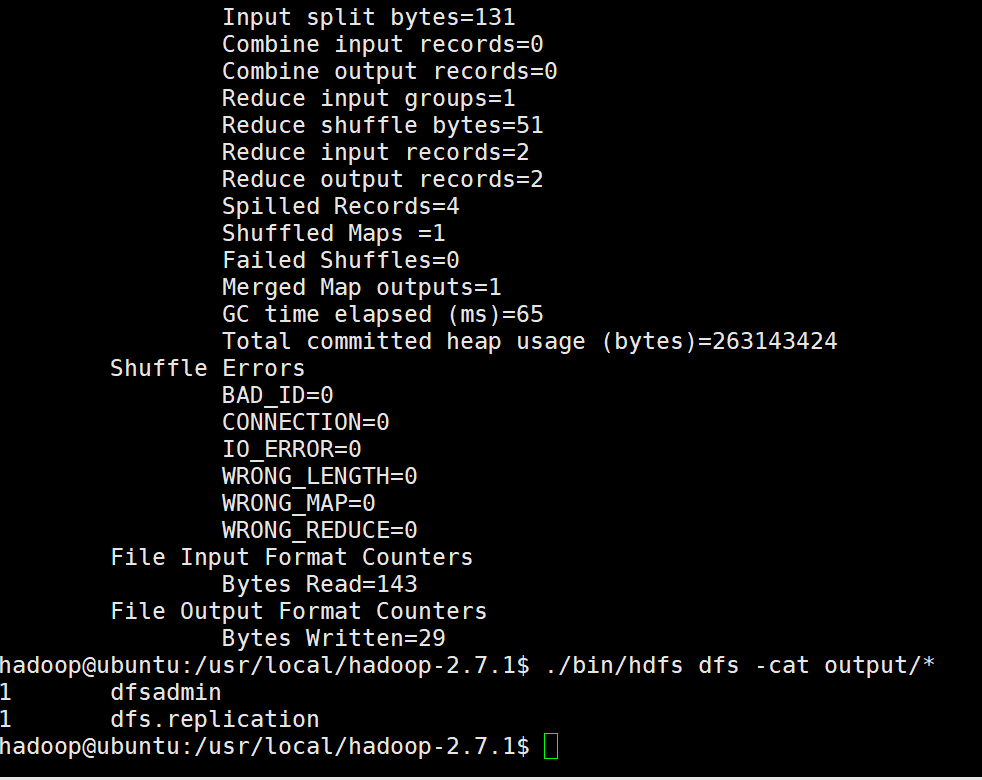
rm -r ./output # 先删除本地的 output 文件夹(如果存在)
./bin/hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
cat ./output/* #输出output文件夹下所有文件
结果如下: 
./sbin/stop-dfs.sh
sudo passwd rootfrom datetime import date
from datetime import datetime
date.formordinal(735190)
from datetime import date
from datetime import datetime
datetime.strftime(x,'%Y-%m-%d')
df.drop(['date'],axis=1) #删除date列
import pandas as pd
dates=pd.date_range('20180222',periods=7)
import pandas as pd
import numpy as np
import matplotlib.pyplot as pt
name=["标题","价格","位置","评分","房屋编号","推荐标签","支付标签","简要描述"]
data=pd.read_csv("data_in_need/tujia.csv",encoding="gbk")
df=pd.DataFrame(data=data,columns=name)
df.评分.unique()
格式为:
df.列名.unique()
或
df["列名"].unique()
 或
或 
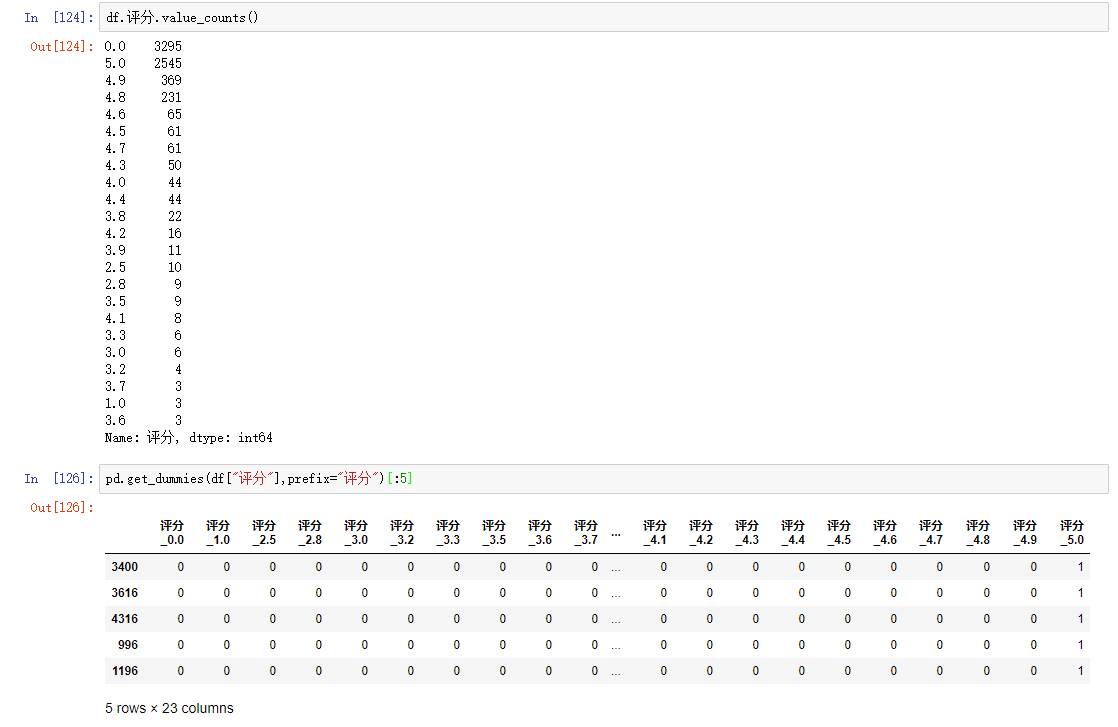
df.评分.value_counts()
格式为:df.列名.value_counts() 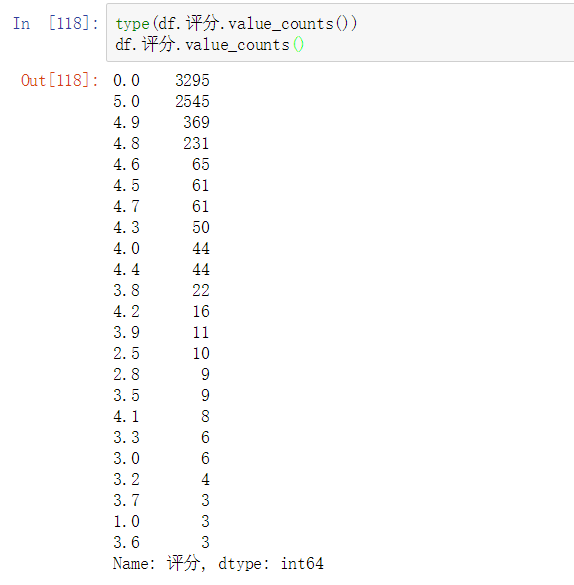
raw['season']=row['season'].apply(lambda x: int(x.split('-')[0]))
去除年份中间的‘-’,取后面的年份 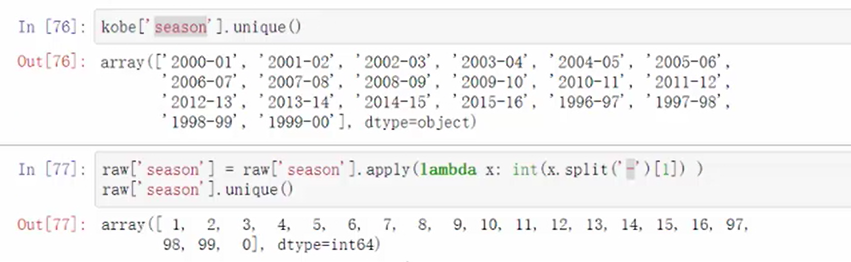
pd.get_dummies(df["评分"],prefix="评分")[:5]
match函数
#encoding:utf-8
import re
pattern=re.compile(r’hello’)
match=pattern.match(‘hello word!!’)
if match:
print(match.group())
split函数
import re
re.split(“\d+”,”one1two2three3four4”)
finditer(迭代器)
import re
content = ‘’’email:12345678@163.com
email:2345678@163.com
email:345678@163.com
‘’’
result=re.finditer(r”\d+@\w+.com”,content)
for m in result:
print(m.group())
findall
import re
re.findall(“\d+”,”one1two2three3four4”)