2017年度职业院校技能大赛(大数据技术与应用赛项 赛题V1)
任务二、数据抓取(30分)
1.现在,网络爬虫抓取到约4G的数据,保存于arg目录的spider.log中,但其中既有电影市场放映信息数据也有其他数据,通过分析数据样本,发现从网站“http://www.movie.com/ bor/”抓取的数据包含有效的电影市场数据,数据中有效数据项包括:电影名称、上映日期、上映场次数、院线城市、导演、演员、影片类型、票房收入,请从spider.log中筛选出一部分有效数据项,并以规定格式保存于ans0201.csv文件中。本题的赛前抽取参数是:数据文件spider.log、需要保存于ans0201.csv文件的有效数据项以及有效数据项的保存格式。
代码如下
import pandas as pd
import numpy as np
data0=pd.read_table("spider.log",sep=",",header=None)
newdata=data0[data0[2].str.contains("票房")]
newdata.head()
newdate内容如下图所示 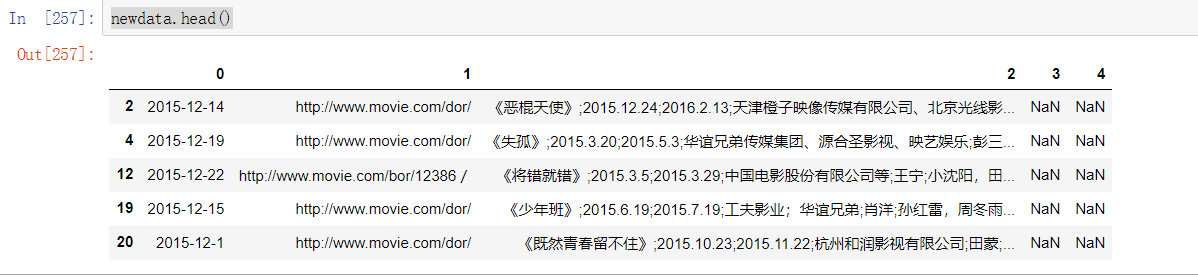
newdata.drop([0,1,3,4],inplace=True,axis=1)
newdata["desc"]=newdata.apply(lambda x:x,axis=0)
newdata.drop([2],inplace=True,axis=1)
newdata.head()
newdate内容如下图所示 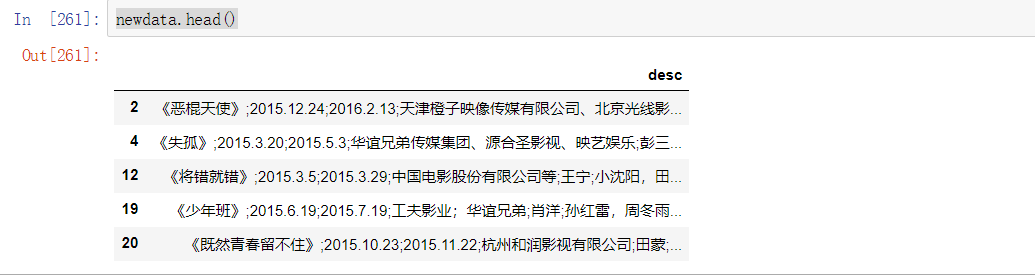
newdata.to_csv("tmp.csv",encoding="utf-8",sep=",",header=None,columns=None,index=None)
tmp=pd.read_csv("tmp.csv",sep=";",header=None)
tmp.head()
tmp内容如下图 
tmp.drop([3,4,5,6,8,9],axis=1,inplace=True)
name=["电影名称","上映日期","结束放映日期","票房收入"]
tmp.to_csv("ans0201.csv",encoding="gbk",sep=",",header=name,index=None)
运行结果
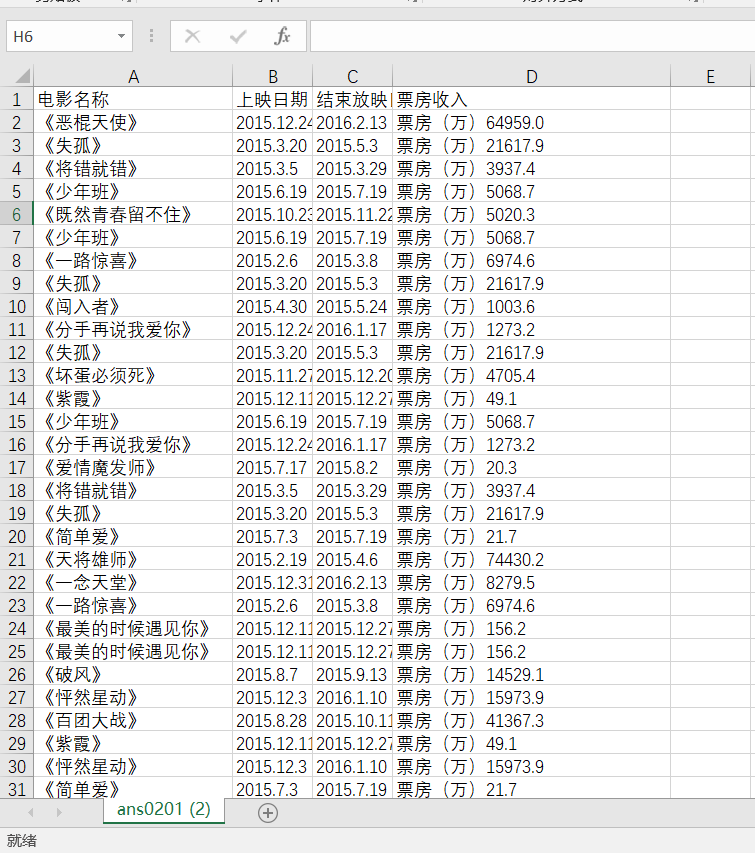
Q3-1
本阶段的任务是:film_log3.csv中包含了不同地区、不同影院的电影票房信息,你的小组通过编程完成对文件film_log3.csv中电影信息数据的清洗和整理,并完成数据计算、分析和表达任务。(20分)
本竞赛任务的赛前抽取参数是:电影名称A、B、C 和地名M市、N市以及数据文件film_log3.csv,选手可在竞赛环境的arg0300.txt文件中获得A、B、C、M、N的值。本任务阶段,需要参赛学生提交每个小题涉及到的所有ansXXXX.jpg、ansXXXX.py、ansXXXX.dat文件(XXXX相关指数字)。 1. 编程统计并输出影片A的上映天数和日平均票房(文件中的所有涉及地区总平均),程序源代码保存成ans0301.py,并将结果保存于ans0301.dat,要求ans0301.dat只包含1个long型数据和一个1个浮点型数据,浮点数据以万元为单位,保留6位小数,2个数以英文逗号分隔,不换行,文件样例如下: 123, 23.123456 分析:因为我没有A电影的标题,因此,我统计所有电影的每日票房,放映天数。
代码如下
#encoding:utf-8
import numpy as np
import pandas as pd
import datetime as dt
name=["filmName","startTime","endTime","co","p1","p2","type","filmRoom","place"]
data0=pd.read_csv("film_log3.csv",sep=';',header=None,names=name)
data0.drop_duplicates(keep="first",inplace=True)
data0.head(3)
filmName
startTime
endTime
co
p1
p2
type
filmRoom
place
0
《冲上云霄》
2015.2.19
2015.3.29
寰亚电影制作有限公司
叶伟信,邹凯光
古天乐,郑秀文,吴镇宇,张智霖,佘诗曼,郭采洁
剧情,爱情
票房(万)1563.3
北京
1
《百团大战》
2015.8.28
2015.10.11
八一电影制片厂;中国电影股份有限公司;北京紫禁城影业公司
宁海强,张玉中
陶泽如,刘之冰,印小天,吴越,唐国强,王伍福
战争/历史
票房(万)4137.3
天津
2
《浪漫天降》
2015.10.23
2015.11.8
NaN
宁瀛
夏雨,关晓彤,邱泽
浪漫,爱情,喜剧
票房(万)75.2
广州
time_form="%Y.%m.%d"
data0.startTime=data0.startTime.apply(lambda x:dt.datetime.strptime(x,time_form))
data0.endTime=data0.endTime.apply(lambda y:dt.datetime.strptime(y,time_form))
data0.startTime.head()
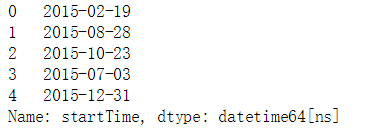
data0.endTime.head()

data0["days"]=data0.endTime-data0.startTime
data0.head(3)
filmName
startTime
endTime
co
p1
p2
type
filmRoom
place
days
0
《冲上云霄》
2015-02-19
2015-03-29
寰亚电影制作有限公司
叶伟信,邹凯光
古天乐,郑秀文,吴镇宇,张智霖,佘诗曼,郭采洁
剧情,爱情
票房(万)1563.3
北京
38 days
1
《百团大战》
2015-08-28
2015-10-11
八一电影制片厂;中国电影股份有限公司;北京紫禁城影业公司
宁海强,张玉中
陶泽如,刘之冰,印小天,吴越,唐国强,王伍福
战争/历史
票房(万)4137.3
天津
44 days
2
《浪漫天降》
2015-10-23
2015-11-08
NaN
宁瀛
夏雨,关晓彤,邱泽
浪漫,爱情,喜剧
票房(万)75.2
广州
16 days
import re
data0.filmRoom=data0.filmRoom.apply(lambda x:float(re.findall("\d+\.\d+",x)[0]))
data0.filmRoom.head()

data0.head()
filmName
startTime
endTime
co
p1
p2
type
filmRoom
place
days
0
《冲上云霄》
2015-02-19
2015-03-29
寰亚电影制作有限公司
叶伟信,邹凯光
古天乐,郑秀文,吴镇宇,张智霖,佘诗曼,郭采洁
剧情,爱情
1563.3
北京
38 days
1
《百团大战》
2015-08-28
2015-10-11
八一电影制片厂;中国电影股份有限公司;北京紫禁城影业公司
宁海强,张玉中
陶泽如,刘之冰,印小天,吴越,唐国强,王伍福
战争/历史
4137.3
天津
44 days
2
《浪漫天降》
2015-10-23
2015-11-08
NaN
宁瀛
夏雨,关晓彤,邱泽
浪漫,爱情,喜剧
75.2
广州
16 days
3
《简单爱》
2015-07-03
2015-07-19
中视合利(北京)文化投资有限公司一鸣影业公司(美国)
崔龄燕
许绍洋,张琳,谢雨芩,石铭熙
都市浪漫爱情喜剧
232.7
成都
16 days
4
《一念天堂》
2015-12-31
2016-02-13
天河盛宴,凯德盛世(北京)投资管理有限公司,和云筹(北京)网络科技有限公司
张承
沈腾,马丽,林雪,杜晓宇,王子子,李元鹏
喜剧
829.5
沈阳
44 days
data0["days"]=data0.days.apply(lambda x:x.days)
FN=data0.filmName.unique()
FN

all_days=[]
all_money=[]
for title in FN:
all_days.append(float(data0[data0.filmName.str.contains(title)].loc[:,["days"]].sum()))
all_money.append(float(data0[data0.filmName.str.contains(title)].loc[:,["filmRoom"]].sum()))
all_money[:3]
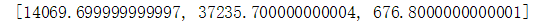
F={"FName":FN,"all_days":all_days,"Money":all_money}
result=pd.DataFrame(F)
result
FName
Money
all_days
0
《冲上云霄》
14069.7
342.0
1
《百团大战》
37235.7
396.0
2
《浪漫天降》
676.8
144.0
3
《简单爱》
2094.3
144.0
4
《一念天堂》
7465.5
396.0
5
《爱之初体验》
253.6
128.0
6
《紫霞》
32.8
128.0
7
《一路惊喜》
8771.4
270.0
8
《失孤》
17343.2
352.0
9
《闯入者》
932.4
216.0
10
《探灵档案》
272.8
120.0
11
《坏蛋必须死》
3243.2
184.0
12
《万物生长》
12886.2
333.0
13
《破风》
12861.9
333.0
14
《最美的时候遇见你》
136.8
144.0
15
《将错就错》
3576.6
216.0
16
《少年班》
4560.3
270.0
17
《分手再说我爱你》
1385.6
192.0
18
《既然青春留不住》
4502.7
270.0
19
《前任2:备胎反击战》
17601.6
352.0
20
《爱情魔发师》
18.4
128.0
21
《天将雄师》
66988.8
414.0
22
《怦然星动》
14345.1
342.0
23
《恶棍天使》
58455.0
459.0
result["average_day_money"]=result.Money/result.all_days
result
FName
Money
all_days
average_day_money
0
《冲上云霄》
14069.7
342.0
41.139474
1
《百团大战》
37235.7
396.0
94.029545
2
《浪漫天降》
676.8
144.0
4.700000
3
《简单爱》
2094.3
144.0
14.543750
4
《一念天堂》
7465.5
396.0
18.852273
5
《爱之初体验》
253.6
128.0
1.981250
6
《紫霞》
32.8
128.0
0.256250
7
《一路惊喜》
8771.4
270.0
32.486667
8
《失孤》
17343.2
352.0
49.270455
9
《闯入者》
932.4
216.0
4.316667
10
《探灵档案》
272.8
120.0
2.273333
11
《坏蛋必须死》
3243.2
184.0
17.626087
12
《万物生长》
12886.2
333.0
38.697297
13
《破风》
12861.9
333.0
38.624324
14
《最美的时候遇见你》
136.8
144.0
0.950000
15
《将错就错》
3576.6
216.0
16.558333
16
《少年班》
4560.3
270.0
16.890000
17
《分手再说我爱你》
1385.6
192.0
7.216667
18
《既然青春留不住》
4502.7
270.0
16.676667
19
《前任2:备胎反击战》
17601.6
352.0
50.004545
20
《爱情魔发师》
18.4
128.0
0.143750
21
《天将雄师》
66988.8
414.0
161.808696
22
《怦然星动》
14345.1
342.0
41.944737
23
《恶棍天使》
58455.0
459.0
127.352941
Q3-2
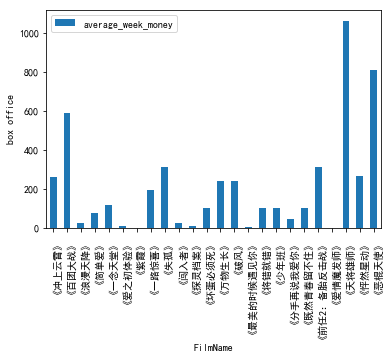
编程绘制一个直方图,在图中输出影片A、B、C的周平均票房(文件中的所有涉及地区周票房总平均),Y轴表示票房收入,单位万元;X轴表示电影名称,电影名称的排列从左至右以A、B、C为准,要求将输出的直方图保存成图像文件ans0302.jpg,程序源代码保存成ans0302.py,另外,将三部电影各自的票房总收入按自高到低的顺序存入ans0302.dat文件中,要求ans0302.dat中只包含3个浮点型票房数据,以万元为单位,保留6位小数,数据以英文逗号分隔,不换行,文件样例如下: 23.123456,20.654321,18.123456 对本题周票房的说明如下:若某部电影从某月2日开始上映,则从当月2日到8日为其第1周票房,9日至15日为其第2周票房,不满1周按1周计算以此类推。
代码如下
会引用上面处理过的result列表等
from matplotlib import pyplot as plt
def getweek(days):
if days%7==0:
return days/7
else:
return days//7+1
data0["weeks"]=data0.days.apply(lambda x:getweek(x))
data0.head()
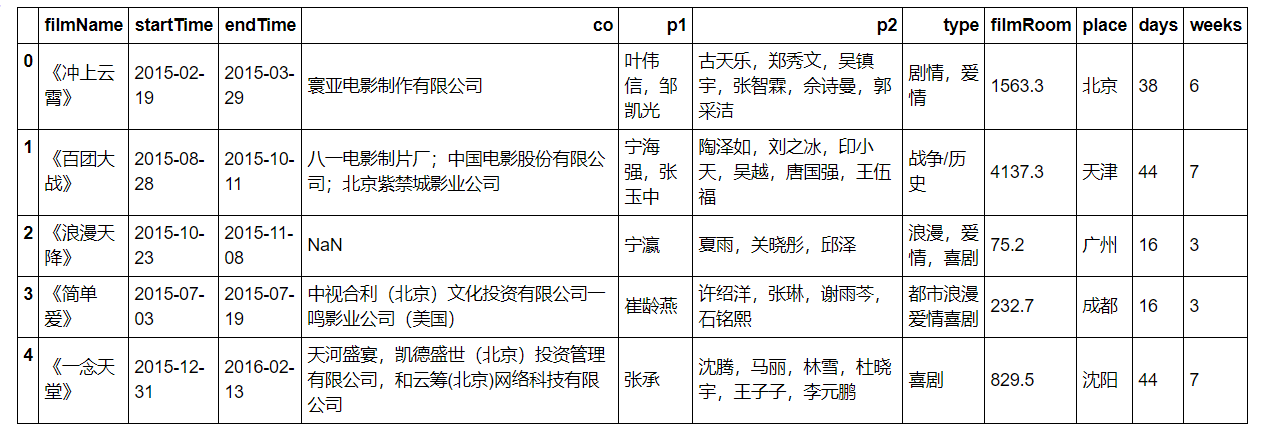
weeks=[]
for title in FN:
weeks.append(int(data0[data0.filmName.str.contains(title)].loc[:,["weeks"]].sum()))
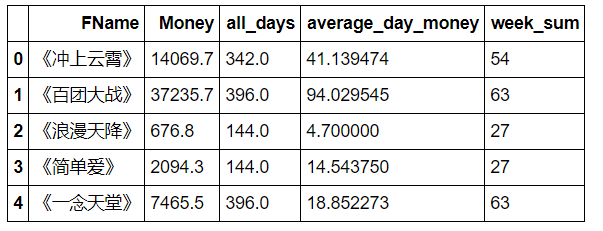
result["week_sum"]=pd.DataFrame(weeks)
result.head()
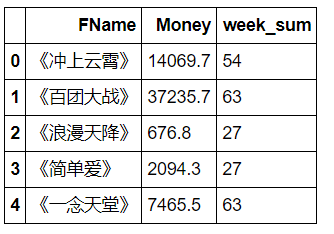
Q2=result.drop(["all_days","average_day_money"],axis=1)
Q2.head()
Q2["average_week_money"]=Q2.Money/Q2.week_sum
Q2.head()
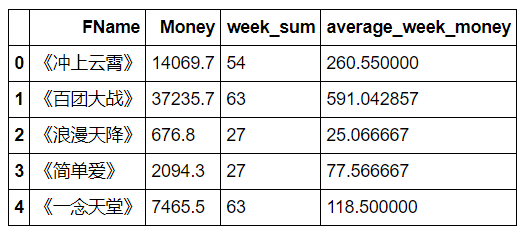
pic_data=Q2.drop(["Money","week_sum"],axis=1)
pic_data.set_index("FName",inplace=True)
pic_data.head()
pic_data.plot(kind="bar")
plt.xlabel("FilmName")
plt.ylabel("box office")
plt.show()
pic_data.to_csv("ans0302.dat",sep=",",index=None,header=None) #保存,需要手工换在一行上。