1. 获取DateFrame中一列中包含的属性(不同的值(去重))
import pandas as pd
import numpy as np
import matplotlib.pyplot as pt
name=["标题","价格","位置","评分","房屋编号","推荐标签","支付标签","简要描述"]
data=pd.read_csv("data_in_need/tujia.csv",encoding="gbk")
df=pd.DataFrame(data=data,columns=name)
df.评分.unique()
格式为:
df.列名.unique()
或
df["列名"].unique()
 或
或 
2. DateFrame中的某一列属性的重复次数统计(计数)
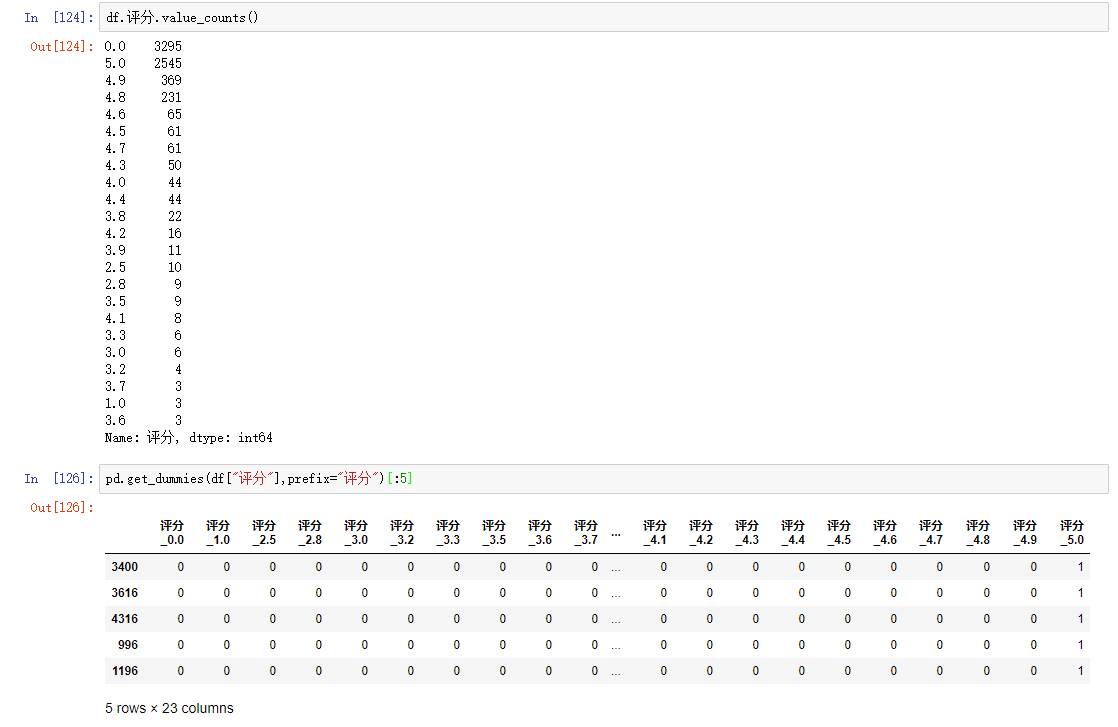
df.评分.value_counts()
格式为:df.列名.value_counts() 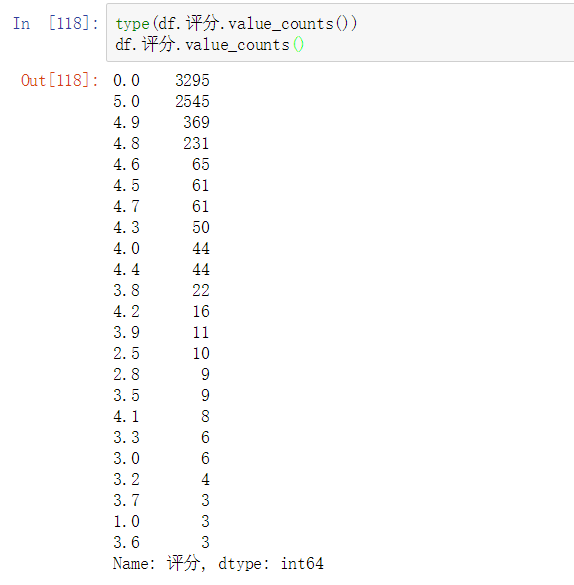
3. 处理特殊字符数据
raw['season']=row['season'].apply(lambda x: int(x.split('-')[0]))
去除年份中间的‘-’,取后面的年份 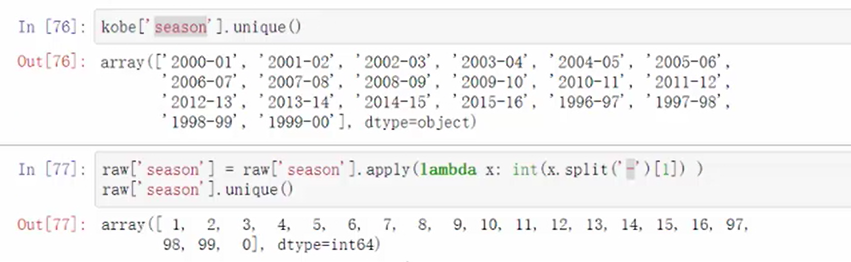
4. onehot编码
pd.get_dummies(df["评分"],prefix="评分")[:5]